Abstract
Speech-driven gesture generation is an emerging field within virtual human creation. However, a significant challenge lies in accurately determining and processing the multitude of input features (such as acoustic, semantic, emotional, personality, and even subtle unknown features). Traditional approaches, reliant on various explicit feature inputs and complex multimodal processing, constrain the expressiveness of resulting gestures and limit their applicability.
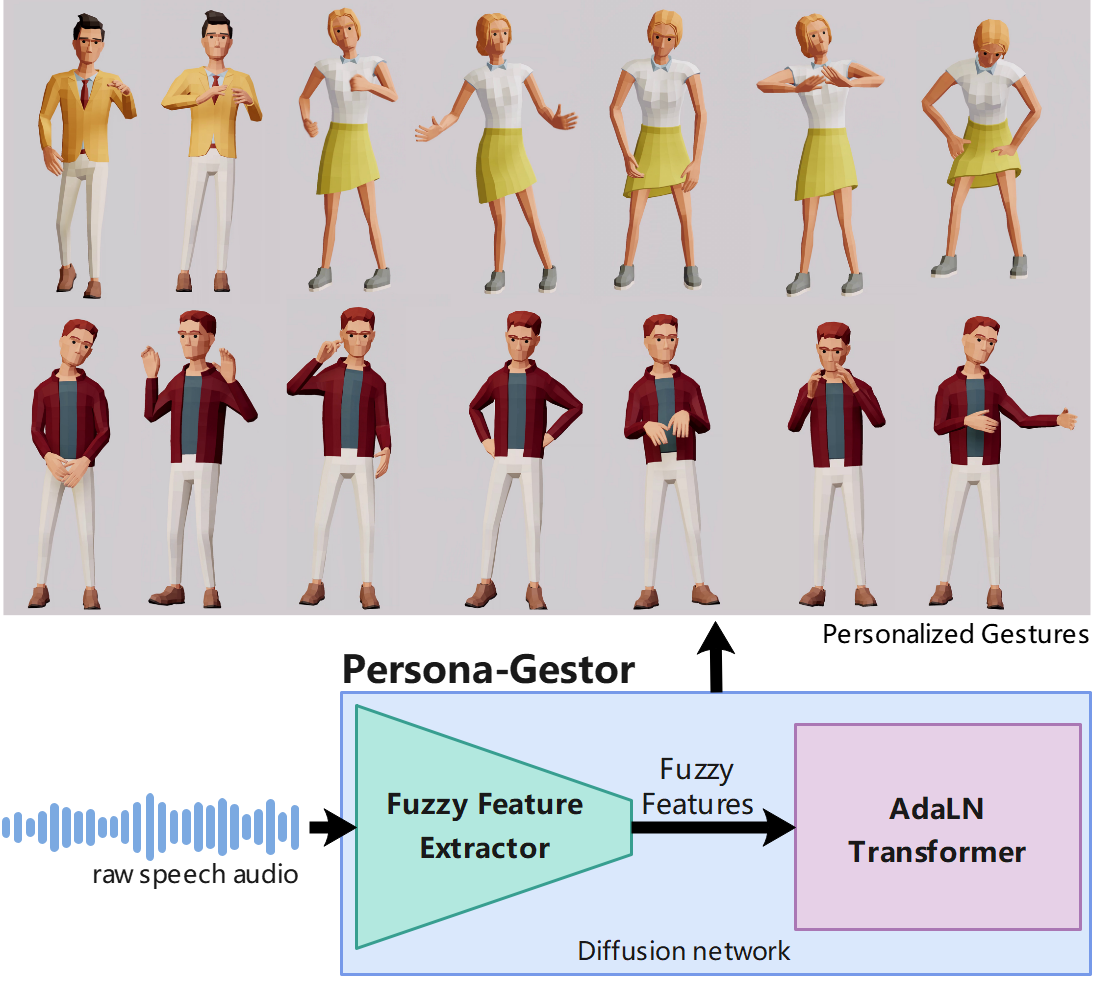
To address these challenges, we present Persona-Gestor, a novel end-to-end generative model designed to generate highly personalized 3D full-body gestures solely relying on raw speech audio. The model combines a fuzzy feature extractor and a non-autoregressive Adaptive Layer Normalization (AdaLN) transformer diffusion architecture. The fuzzy feature extractor harnesses a fuzzy inference strategy that automatically infers implicit, continuous fuzzy features. These fuzzy features, represented as a unified latent feature, are fed into the AdaLN transformer. The AdaLN transformer introduces a conditional mechanism that applies a uniform function across all tokens, thereby effectively modeling the correlation between the fuzzy features and the gesture sequence. This module ensures a high level of gesture-speech synchronization while preserving naturalness. Finally, we employ the diffusion model to train and infer various gestures. Extensive subjective and objective evaluations on the Trinity, ZEGGS, and BEAT datasets confirm our model's superior performance to the current state-of-the-art approaches.
Persona-Gestor improves the system's usability and generalization capabilities, setting a new benchmark in speech-driven gesture synthesis and broadening the horizon for virtual human technology.
Our contributions are summarized as follows:
1) We pioneering introduce the fuzzy feature inference strategy that enables driving a wider range of personalized gesture synthesis from speech audio alone, removing the need for style labels or extra inputs.
This fuzzy feature extractor improves the usability and the generalization capabilities of the system. To the best of our knowledge, it is the first approach that uses fuzzy features to generate co-speech personalized gestures.
2) We combined AdaLN transformer architecture within the diffusion model to enhance the Modeling of the gesture-speech interplay. We demonstrate that this architecture can generate gestures that achieve an optimal balance of natural and speech synchronization.
3) Extensive subjective and objective evaluations reveal our model superior outperform to the current state-of-the-art approaches. These results show the remarkable capability of our method in generating credible, speech-appropriateness, and personalized gestures.
References
@ARTICLE{zhang2024PersonalizedGesture,
author={Zhang, Fan and Wang, Zhaohan and Lyu, Xin and Zhao, Siyuan and Li, Mengjian and Geng, Weidong and Ji, Naye and Du, Hui and Gao, Fuxing and Wu, Hao and Li, Shunman},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Speech-driven Personalized Gesture Synthetics: Harnessing Automatic Fuzzy Feature Inference},
year={2024},
volume={},
number={},
pages={1-16},
keywords={Feature extraction;Transformers;Art;Synchronization;Semantics;Fuzzy logic;Adaptation models;Speech-driven;Gesture synthesis;Fuzzy inference;AdaLN;Diffusion;Transformer;DiTs},
doi={10.1109/TVCG.2024.3393236}}
@Article{Zhang2024DiTGesture,
AUTHOR = {Zhang, Fan and Wang, Zhaohan and Lyu, Xin and Ji, Naye and Zhao, Siyuan and Gao, Fuxing},
TITLE = {DiT-Gesture: A Speech-Only Approach to Stylized Gesture Generation},
JOURNAL = {Electronics},
VOLUME = {13},
YEAR = {2024},
NUMBER = {9},
ARTICLE-NUMBER = {1702},
URL = {https://www.mdpi.com/2079-9292/13/9/1702},
ISSN = {2079-9292},
DOI = {10.3390/electronics13091702}
}
BEAT
The results obtained by train and inference on the BEAT dataset have substantiated the proposed methodology's capacity to generate distinct personality gestures based solely on speech audio, encompassing a total of 30 different speakers.
solomon_0_46_46
wayne_0_39_39
lawrence_0_5_5
zhao_0_88_88
lu_0_9_9
stewart_0_9_9
carla_0_96_96
sophie_0_6_6
zhang_1_3_3
carlos_0_2_2
miranda_1_12_12
kieks_0_9_9
nidal_0_66_66
itoi_0_111_111
daiki_0_73_73
jaime_0_96_96
li_0_95_95
luqi_0_88_88
hailing_0_10_10
kexin_0_111_111
goto_0_74_74
reamey_0_3_3
yingqing_0_9_9
tiffnay_0_74_74
hanieh_0_4_4
ZEGGS
The samples, obtained by utilizing a variety of audio styles (a total of 19 styles) from the ZEGGS dataset, result in a broad spectrum of motion styles.
Neutral_0_x_0_9
Sad_0_x_0_9
Happy_0_x_1_0
Relaxed_0_x_1_0
Old_1_x_0_9
Angry_0_x_0_9
Agreement_0_x_1_0
Disagreement_0_x_1_0
Flirty_0_x_1_0
Pensive_0_x_0_9
Scared_0_x_0_9
Distracted_0_x_0_9
Threatening_0_x_1_0
Threatening_1_x_0_9
Still_1_x_0
Sneaky_1_x_0
Laughing_0_x_0_9
Tired_1_x_0_9
Speech_0_x_1_0
Sarcastic_0_x_0_9
Trinity
The full-body gesture sequences generated by the model trained on the Trinity dataset are displayed in response to the audio from Record_008.wav (right) and Record_015.wav (left), separately. The two rows on each side represent a pair of diverse gestures generated in response to the same speech audio.
Movie_Recording_008_01
Movie_Recording_015_01
Generalization and Robustness
We test our method’s generalization capabilities. We utilized in-the-wild speech audio collected from TED talks. Our system adeptly generates consistent gestures from dataset types and seamlessly produces gestures from untagged, in-the-wild audio. It also showcases remarkable robustness against various auditory disturbances, such as background music, applause, urban noise, and decorative sounds.
Note : The videos are concatenated every 20 seconds, resulting in a discontinuity at the 20-second mark.
TEDNoise_PG_CarmenAgraDeedy_2005_noise_0
TEDNoise_PGL_CharmianGooch_2013G_noise_0
TEDNoise_PG_JohnSearle_2013_noise_0
TEDNoise_PG_JonathanFoley_2010X_noise_0
TEDNoise_PG_StefanaBroadbent_2009G_noise_0
TEDNoise_PGL_ShereenElFeki_2009G_noise_0